شركة Anthropic تكشف عن نموذج Claude 3.7 Sonnet: نموذج ذكاء اصطناعي يفكر وفقاً لمتطلباتك
⬤ أعلنت Anthropic عن نموذج Claude 3.7 Sonnet بقدرة هجينة على تقديم إجابات سريعة أو تحليلية.
⬤ تفوق النموذج الجديد في اختبارات الأداء، على نماذج OpenAI في مهام البرمجة والتفاعل مع المستخدمين.
⬤ طرحت Anthropic أداة Claude Code المخصصة للمطورين، لمساعدتهم في تحليل الأكواد وإدارتها.
أعلنت Anthropic عن إطلاق نموذجها الأحدث Claude 3.7 Sonnet، والذي يمثل خطوة متقدمة في تصميم أنظمة الذكاء الاصطناعي، فهو ليس مجرد تحديث تقليدي، بل تم تطويره ليكون بمثابة «ذكاء اصطناعي هجين في الاستدلال،» يجمع بين القدرة على تقديم إجابات سريعة للغاية وإجابات متأنية وعميقة التفكير ضمن نظام واحد.
على خلاف النماذج المعقدة التي تتطلب من المستخدمين الاختيار بين إصدارات متعددة وفقاً للتكلفة والقدرات، تسعى Anthropic إلى تبسيط التجربة مع Claude 3.7 Sonnet كنموذج شامل ومرن، يكون فيه الاستدلال «جزءاً جوهرياً من الذكاء الاصطناعي، وليس مجرد ميزة منفصلة،» وفقاً لديان بين، المسؤولة عن المنتج والبحث في Anthropic.

بدأ طرح Claude 3.7 Sonnet للمستخدمين والمطورين اعتباراً من الاثنين، 25 فبراير، عبر تطبيق Claude، ومنصة Anthropic API، وخدمات Amazon Bedrock ومنصةVertex AI من Google Cloud. في حين سيحصل المشتركون بالمجان على نسخة معيارية من النموذج.
يتميز النموذج الجديد بقدرته على التفكير بناء على مدة زمنية يحددها المستخدم، سواء للإجابات السريعة أو لحل المشكلات المعقدة. وتشكل خاصية «الاستدلال الهجين» نقطة تحول في الذكاء الاصطناعي؛ حيث يمكن للنموذج التفاعل بذكاء وسرعة مع الأسئلة البسيطة مثل السؤال عن الوقت، ويخصص مزيداً من التحليل والتفكير للأسئلة الأكثر تعقيداً، بالاعتماد على تفكيك المشكلات المعقدة إلى خطوات أصغر، مما يعزز من دقة الاستنتاجات.
في خطوة لزيادة الشفافية، توفر Anthropic ميزة تتيح للمستخدمين الاطلاع على مراحل تحليل الذكاء الاصطناعي لمعظم الاستفسارات، مع احتمالية إخفاء بعض التفاصيل لأغراض الأمان والثقة.
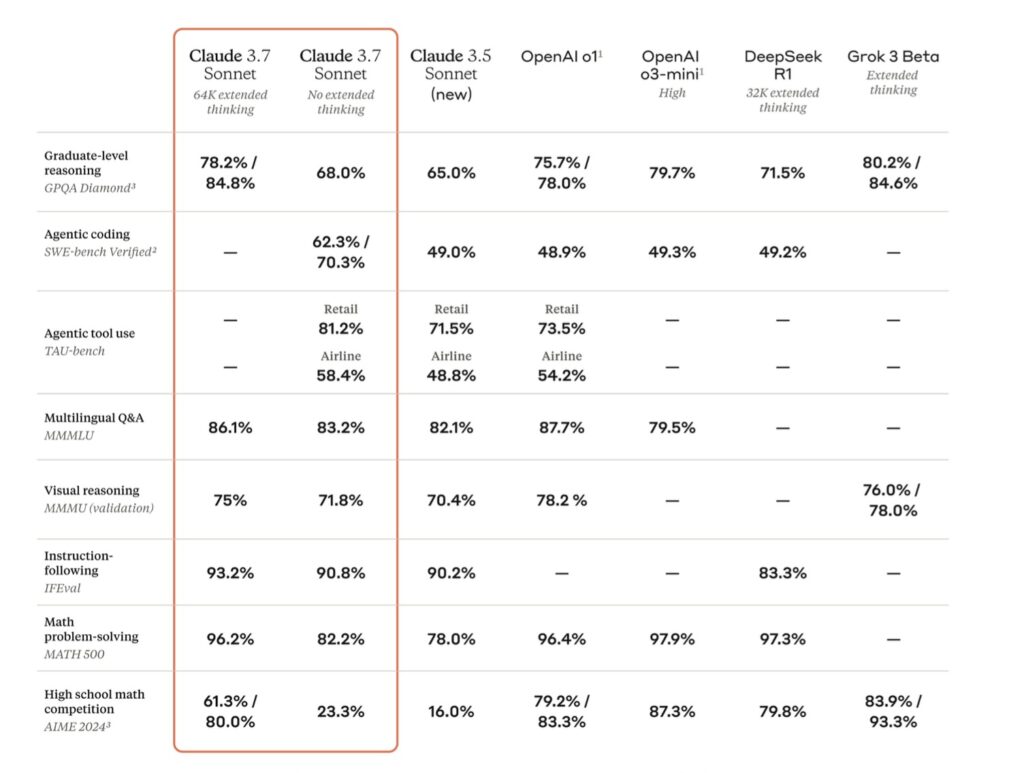
أما على صعيد الأداء، فقد حقق Claude 3.7 Sonnet أرقام مثيرة للاهتمام. ففي اختبار SWE-Bench، المتخصص في تقييم المهام البرمجية الواقعية، سجل النموذج دقة بلغت 62.3%، متفوقاً على نموذج o3-mini من OpenAI الذي حقق 49.3%. كما أحرز في اختبار TAU-Bench، الذي يحاكي التفاعل مع المستخدمين، نسبة 81.2% مقارنة بنسبة 73.5% لنموذج o1 من OpenAI. وقد استخدمت Anthropic لاختبار النموذج أيضاً لعبة Pokémon، ليتمكن من اجتياز مستويات متقدمة فيها.
بالتزامن مع هذا الإطلاق، كشفت Anthropic عن أداة جديدة تحمل اسم Claude Code، وهي أشبه بأداة برمجية «وكيلة» متاحة في إطار معاينة بحثية محدودة. وتتيح للمطورين التفاعل مع Claude مباشرة من خلال بيئة الأوامر النصية، حيث يمكنها تحليل الأكواد، وتعديل الملفات، وكتابة الاختبارات وتشغيلها، وحتى إدارة مستودعات الأكواد على GitHub.
يأتي Claude 3.7 Sonnet بسعر أعلى نسبياً من بعض المنافسين مثل o3-mini من OpenAI وR1 من DeepSeek، وترى Anthropic أن قدراته الهجينة وإمكاناته المتقدمة تبرر هذه التكلفة. إذ يبلغ سعر النموذج 3 دولارات لكل مليون رمز إدخال و15 دولاراً لكل مليون رمز إخراج، وهي نفس تكلفة سابقه Claude 3.5 Sonnet.
من بين التحسينات الملحوظة، سجل النموذج انخفاضاً بنسبة 45% في رفض الإجابة عن الأسئلة دون داعٍ، مقارنة بالإصدار السابق، في خطوة تعكس توجهاً نحو نهج أكثر دقة وأقل تقييداً في سياسات أمان الذكاء الاصطناعي، تماشياً مع إعادة تقييم أوسع في القطاع عامة.