دراسة: محركات البحث بالذكاء الاصطناعي تعطي إجابات خاطئة أو مضللة أكثر من الصحيحة

⬤ كشفت دراسة حديثة أن محركات البحث بالذكاء الاصطناعي تخطئ بنسبة 60%، مما يثير مخاوف حول موثوقيتها.
⬤ أظهرت الدراسة أن هذه المحركات تعاني من صعوبة في تقديم استشهادات دقيقة وتختلق معلومات وروابط وهمية.
⬤ رغم التكلفة المرتفعة للنسخ المدفوعة منها، فهي ليست أدق، بل أنها تؤدي أسوأ من المجانية حتى في بعض الحالات.
كشفت دراسة حديثة عن مشكلات خطيرة تتعلق بدقة محركات البحث المعتمدة على الذكاء الاصطناعي، مما يثير تساؤلات حول موثوقيتها كمصادر للمعلومات. وأظهرت الدراسة الشاملة، التي أجراها مركز Tow للصحافة الرقمية التابع لمجلة Columbia Journalism Review، أن هذه الأدوات الذكية تخطئ بنسبة صادمة تصل إلى 60% وسطياً، وهو ما يقوض وعودها بتقديم نتائج بحث دقيقة يمكن الاعتماد عليها.
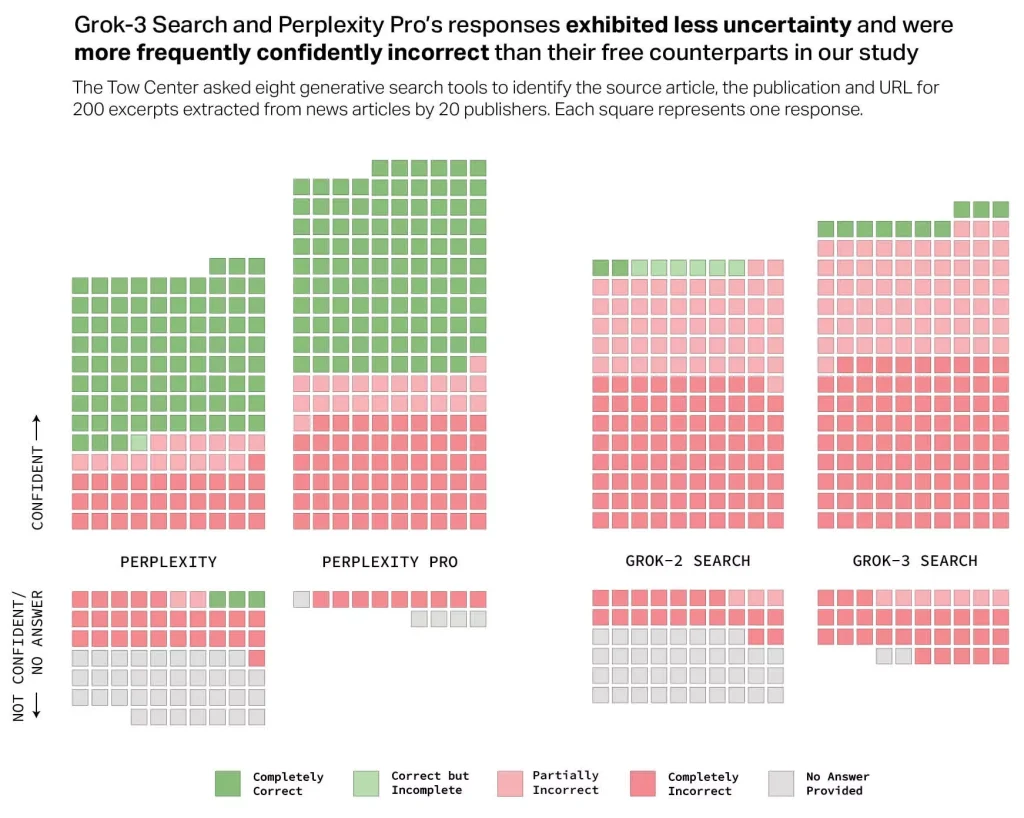
شمل البحث تقييماً دقيقاً لثمانية من أبرز محركات البحث بالذكاء الاصطناعي، من بينها ChatGPT Search من OpenAI، وGemini من Google، وCopilot من Microsoft، بالإضافة إلى Perplexity ونسخته المدفوعة Perplexity Pro، إلى جانب DeepSeek Search ومحركي Grok-2 وGrok-3 من X. وقام الباحثون بتحليل إجابات هذه الأدوات باستخدام 200 مقال إخباري منشور في مؤسسات إعلامية موثوقة.
رغم أن محركي Perplexity وPerplexity Pro قدما أداء أفضل نسبياً مقارنة بالمنافسين، إلا أن النتيجة العامة كانت بعيدة عن الاطمئنان. فقد أظهرت جميع هذه المحركات صعوبة كبيرة في تقديم استشهادات دقيقة تتعلق بالمقال الأصلي أو المصدر الإخباري أو حتى عنوان URL الخاص به. ووفقاً لمقياس الدقة الذي اعتمدته الدراسة، والذي تراوح بين «صحيح تماماً» و«خاطئ تماماً،» فإن معدل الخطأ الإجمالي بلغ 60%.

بالحديث عن الأرقام، فرغم إجابته على جميع الأسئلة البالغ عددها 200، لم يحقق ChatGPT Search سوى نسبة 28% من الإجابات الصحيحة تماماً، في حين بلغت نسبة الإجابات الخاطئة تماماً 57%. أما Grok-3 Search، فقد قدم الأداء الأسوأ على الإطلاق، فوصلت نسبة عدم الدقة إلى مستوى 94%. من جهته، واجه Copilot صعوبات كبيرة، إذ امتنع عن الإجابة على 104 من أصل 200 استفسار. أما إجاباته المتبقية، فقد كانت 16 منها فقط صحيحة تماماً، بينما اتسمت الغالبية العظمى، أي ما يقارب 70%، بعدم الدقة.
تؤكد هذه البيانات ما كان يخشاه كثيرون، وهو أن النماذج اللغوية الضخمة (LLMs) التي تشغل هذه المحركات يمكن أن تكون، كما وصفها أحد المعلقين، «أبرع المخادعين على الإطلاق،» حيث تقدم معلومات ملفقة بثقة مطلقة حتى عندما تكون خاطئة تماماً. وقد لاحظ الباحثون تكرار هذا النمط، حيث تميل هذه الأنظمة إلى الإصرار على الأخطاء بل وحتى اختلاق معلومات إضافية عند التشكيك في إجاباتها.
إلى جانب هذه المشكلات، سلطت الدراسة الضوء على انتهاكات محتملة تتعلق بأخلاقيات جمع البيانات، حيث تجاهلت بعض محركات البحث بالذكاء الاصطناعي بروتوكولات استبعاد الروبوتات (Robot Exclusion Protocol) التي تفرض قيوداً على استخراج المعلومات. كما تبين أن هذه الأدوات غالباً ما تقدم روابط مختلقة أو تستشهد بمصادر ثانوية ومنسوخة بدلاً من المصدر الأصلي.
تكمن المفارقة الكبرى في التكلفة المرتفعة لبعض هذه الخدمات. فعلى سبيل المثال، تبلغ رسوم الاشتراك الشهري في Perplexity Pro نحو 20 دولاراً، بينما يصل سعر Grok-3 Search إلى 40 دولاراً شهرياً. والمثير للدهشة أن النسخ المدفوعة، رغم تحقيقها معدلات إكمال استفسارات أعلى نسبياً، فقد سجلت معدلات خطأ أعلى من المجانية، مما يثير تساؤلات جوهرية حول جدواها بالنسبة للمستخدمين.
مع ذلك، لم تكن جميع الآراء سلبية. إذ كان لعدد من الصحافيين والمستخدمين انطباعات إيجابية عموماً. لكن بطبيعة الحال، تسلط نتائج الدراسة الضوء على تحد معرفي جوهري يواجه قطاع محركات البحث بالذكاء الاصطناعي قبل أن تكون مصدراً موثوقاً للمعلومات.